Generative models
생성형 모델에 대한 관심이 높다. 생성형 모델이란 무엇인지, 어떻게 작동하는지, 수학적으로 어떤 원리를 바탕으로 하는지 살펴보자.
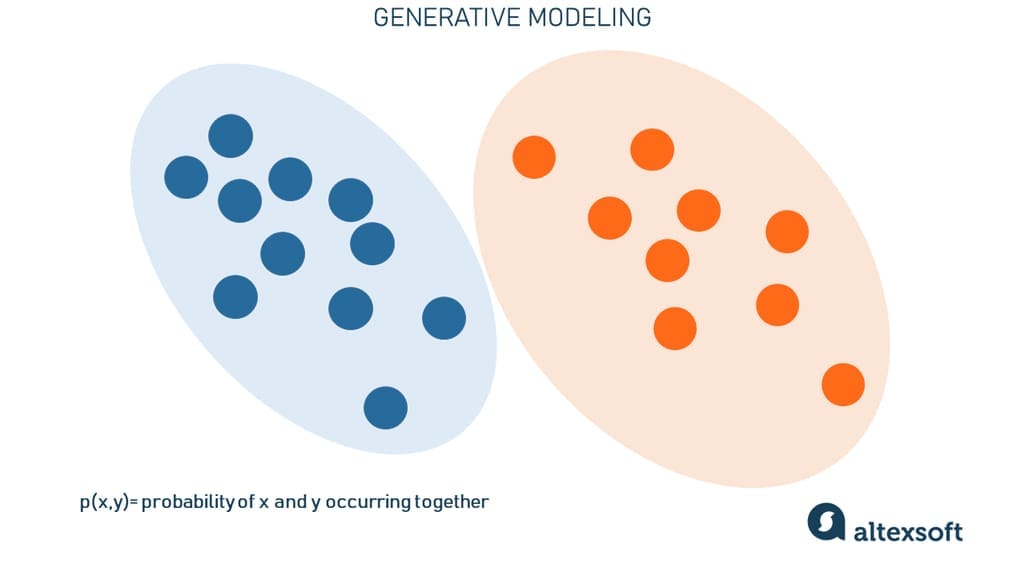
두개의 그룹으로 묶인 샘플들이 있다고 가정하자. 이 분포를 따르는 새로운 샘플을 어떻게 생성할 수 있을까? 우선은 단순히 두개의 분포를 나타내는 확률밀도함수를 기반으로 새로운 시행을 하는 것을 생각해볼 수 있다. 이 확률밀도함수를 추정하는 것이 생성형 모델을 학습하는 과정의 핵심 과제다.
간략하게 생성형 모델의 역사를 들여다보면서, 어떤 모델이 좋은 모델인지에 대해서도 알아보자.

위는 이미지 생성 모델의 결과이다. 어떤 결과가 더 좋은 결과일까? 여기서 보여주고자 하는 것은 이미지의 질이 아니다. 오른쪽으로 갈수록, 같은 대상에 대해 다양한 이미지가 생성된다는 것을 볼 수 있다. 왼쪽은 GAN, 오른쪽은 diffusion 모델이다. 더 다양한 이미지를 보여주는 diffusion model이 더 최신의 architecture이고, 생성형 모델에서는 하나의 class에 대해 다양한 이미지가 생성될 수 있는 것이 favorable하다.
explicit, implicit model로 생성형 모델을 분류할 수도 있다. 위에서 언급한 트레이닝 샘플의 분포를 나타내는 확률밀도함수를 직접 수식으로 정의하고 근사하는 종류의 모델들이 explicit model이다. 수식을 명시적으로(explicitly) 정의하기 때문이다. 반면에 수식을 정확히 정의하지는 않으나, 어쨌든 학습 과정에서 확률밀도함수를 추정하게 되는 종류의 모델도 있다. 이를 implicit model이라고 하고, GAN이 이에 해당한다.
생성형 모델을 평가하는 방법은 여러가지가 있을 수 있는데, 우선 생성된 이미지의 품질을 따질 수 있다. 그런데 품질을 어떻게 평가할 수 있을까? 좋은 품질의 이미지라면, 특정 클래스에 속할 확률이 명확하게 높아야 한다. 예를 들어 가방에 대한 이미지를 생성했는데 해당 이미지가 품질이 뛰어나다면 쉽게 가방으로 분류되어야 한다는 뜻이다. 그런데 가방 이미지를 모두 똑같이 생성한다면, 좋은 모델이 아니다. 따라서 클래스 하나에 속하는 이미지에 대해서는 넓은 분포를 가져야 한다. 또 다른 방법으로는 생성된 이미지의 분포와 실제 이미지의 분포 간 유사도를 비교해볼 수도 있다.
이를 정량화하는 여러가지 metric이 있고, inception score나 Frechet inception distance 등이 그 예시이다. Inception score는 앞서 말한대로 특정 클래스 내의 엔트로피는 높을수록, 특정 이미지의 클래스 라벨 엔트로피는 낮을수록 점수가 높다. Frechet inception distance는 생성된 이미지와 실제 이미지의 분포 간 거리를 따지는 방법이다.
이제 GAN, diffusion model이 각각 어떻게 작동하는지, GAN부터 살펴보자. GAN은 Generative Adversarial Network의 약자다. 생성형 모델과 그 대항마(Adversarial) 네트워크가 서로 경쟁하면서 학습되는 구조를 가지고 있다. 확률분포함수에 대한 정의를 내리지 않으므로 implicit model이다. Generator network는 random noise를 input으로 받아 이미지를 생성하고, discriminator network는 이미지를 input으로 하여, 해당 이미지가 진짜 이미지인지 생성된 이미지인지 구분한다.
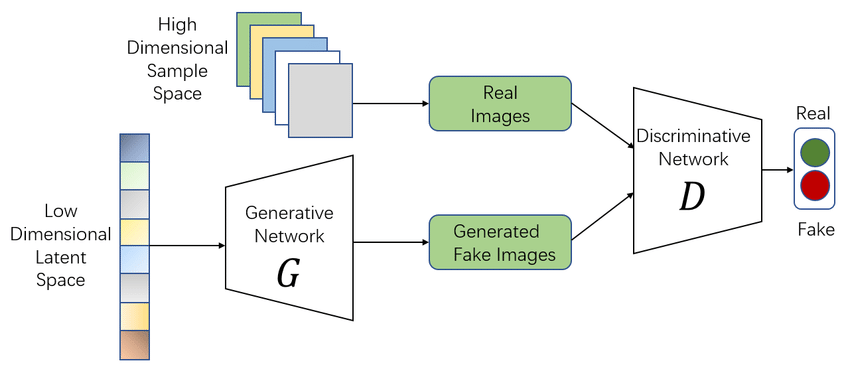
따라서 훈련 과정에서는 generator / discriminator가 번갈아가며 훈련된다. 그런데 실제로는 이 훈련방법이 쉽지 않다. 첫번째 이유는 훈련 초반에는 생성된 이미지와 진짜 이미지를 구분하는 것이 매우 쉽기 때문이다. 따라서 discriminator network의 gradient가 0에 매우 가깝게 되고, gradient vanishing이 일어난다. 따라서 log와 기댓값을 취하는 방식으로 이런 문제를 최소화한다. 두번째 문제는 mode collapse라고 불린다. 간단히 말하면 generator가 discriminator를 속일 수 있는 hack을 찾아내는 상황이다. Discriminator network가 구분하지 못하는 이미지 하나를 포착해서, 그것만 생성하는 식으로 generator network가 손쉽게 이기는 상황이 생긴다. 그러면 더 이상 generator가 훈련되지 않고, 같은 이미지만을 계속해서 생성하게 되므로 훈련이 이루어지지 않는다.
이러한 단점들이 있음에도, GAN을 여러가지 task에 활용해서 훈련시킨 결과물들이 있다. 말을 얼룩말로 바꾸는 모델, 얼굴 이미지를 생성하는 모델에서 출발하여, 텍스트로부터 이미지를 생성하는 모델까지 다양한 GAN 모델이 개발되었다. GAN의 기본 아이디어는 해상도 개선 등 다양한 도메인에 활용될 수 있기 때문이다.
이제 diffusion model로 넘어가보자. 그러려면 우선 autoencoder부터 다시 시작해야 한다.

Autoencoder는 input data를 latent representation으로 나타내는 encoder, latent representation으로부터 원본 데이터를 복원시키는 decoder로 구성된다. 라벨 없이 데이터만 있어도 latent representation을 가능하게 하기 때문에 유용하며, 따라서 보통은 encoder만 사용하고 decoder는 버린다. 그런데, latent representation으로부터 원본 데이터를 생성할 수 있다면 decoder에 random noise를 투입하면 새로운 데이터를 생성할 수 있을까?
결론은 그렇지 않다. Latent representation의 분포를 모르기 때문이다. Autoencoder를 훈련하는 과정에서 latent space에 대한 제한을 걸지 않으면 random noise가 의미 있는 데이터와 연관된다는 보장이 없다. 유의미한 데이터를 생성하려면 latent representation과 유사한 input을 decoder에 주어야 한다.
이를 해결하기 위해 variational autoencoder(VAE)가 등장했다. VAE의 encoder는 probabilistic encoder라고 한다. 기존의 autoencoder는 같은 input이 주어지면 latent representation이 반드시 같은 deterministic model이다. 반면, VAE의 encoder는 확률론적인 개념을 도입해서 input이 주어졌을 때 latent representation을 평균과 분산을 이용해 표현한다. 이후 실제 representation은 이 확률 분포에서 sampling하여 가져온다. 수학적으로는 먼저 latent space의 분포(prior distribution)를 가정하고, input x가 주어졌을 때의 조건부 확률밀도함수의 평균과 분산을 encoder가 출력하는 것이다. 훈련할 때에는 원본 데이터의 likelihood를 최대화하는 방향으로 훈련한다. 또한 데이터 생성을 위해 만들어진 네트워크이므로 encoder를 버리고 decoder를 사용하게 된다.
이제 마지막으로 diffusion model에 대해 알아보자.

Diffusion model은 원본 이미지에 서서히 노이즈를 추가한 과정을 거꾸로 돌리는 법을 학습하는 모델이다. 임의의 이미지 X가 있을 때, Gaussian noise를 조금씩 추가하면 이미지 데이터셋의 분포는 Gaussian distribution이 된다. 이는 VAE에서 latent representation이 특정 분포를 따르게끔 유도되는 것과 유사하다.
단계적으로 진행되는 프로세스를 Markov chain이라고 하며, 단계가 길수록 연산 시간이 오래 걸릴 수밖에 없다. 이때 forward process의 경우 직접 모든 단계를 계산할 필요 없이 특정 단계의 X를 즉시 계산할 수 있어 시간이 오래 걸리지 않는다.
거꾸로 random noise로부터 원본 이미지까지 가는 과정을 생각해보자. Forward process를 어떻게 되돌릴 수 있을까? 핵심은 \(P(X_{t-1} \mid X_t)\)을 학습하는 것에 있다. 현 상태에서 한 단계씩 이전 이미지를 추정하는 것이다.